18. Mashup: APIs, Downloading Files Programmatically, JSON
Mashup: APIs, Downloading Files Programmatically, and JSON
With APIs, downloading files programmatically from the internet, and JSON under your belt, you now have all of the knowledge to download all of the movie poster images for the Roger Ebert review word clouds. This is your next task.
There are two key things to be aware of before you begin:
1. Wikipedia Page Titles
To access Wikipedia page data via the MediaWiki API with wptools ( phew , that was a mouthful), you need each movie's Wikipedia page title, i.e., what comes after the last slash in en.wikipedia.org/wiki/ in the URL. For this lesson, I've compiled all of these titles for each of the movies in the Top 100 for you.
2. Downloading Image Files
Downloading images may seem tricky from a reading and writing perspective, in comparison to text files which you can read line by line, for example. But in reality, image files aren't special—they're just binary files. To interact with them, you don't need special software (like Photoshop or something) that "understands" images. You can use regular file opening, reading, and writing techniques, like this:
import requests
r = requests.get(url)
with open(folder_name + '/' + filename, 'wb') as f:
f.write(r.content)But this technique can be error-prone. It will work most of the time, but sometimes the file you write to will be damaged. This happened to me when preparing this lesson:
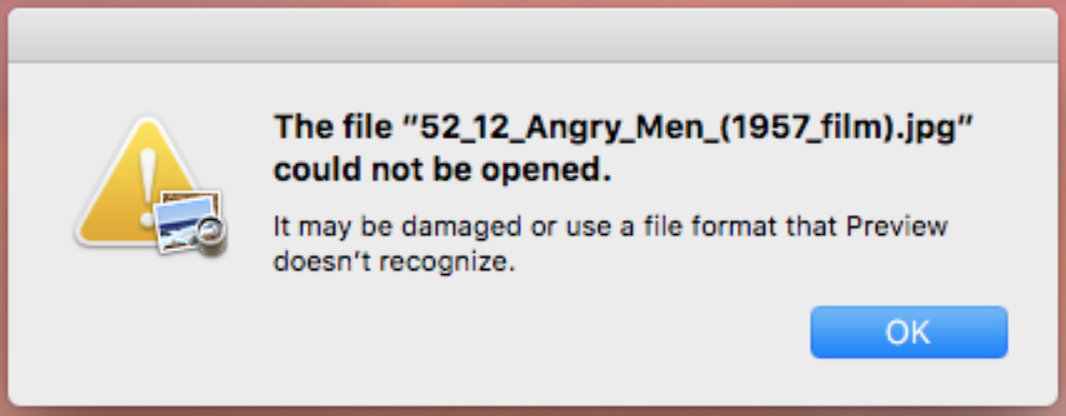
This type of error is why the
requests
library maintainers
recommend
using the
PIL
library (short for Pillow) and
BytesIO
from the
io
library for non-text requests, like images. They recommend that you access the response body as bytes, for non-text requests. For example, to create an image from binary data returned by a request:
import requests
from PIL import Image
from io import BytesIO
r = requests.get(url)
i = Image.open(BytesIO(r.content))Though you may still encounter a similar file error, this code above will at least warn us with an error message, at which point we can manually download the problematic images.
Quiz
Let's gather the last piece of data for the Roger Ebert review word clouds now: the movie poster image files. Let's also keep each image's URL to add to the master DataFrame later.
Though we're going to use a loop to minimize repetition, here's how the major parts inside that loop will work, in order:
-
We're going to query the MediaWiki API using
wptools
to get a movie poster URL via each page object's
imageattribute. - Using that URL, we'll programmatically download that image into a folder called bestofrt_posters .
This one's a doozy, so take your time. If you get stuck, the solution is presented in full Jupyter Notebook-form on the next page.
The Jupyter Notebook below contains template code that:
- Contains title_list , which is a list of all of the Wikipedia page titles for each movie in the Rotten Tomatoes Top 100 Movies of All Time list. This list is in the same order as the Top 100.
- Creates an empty list, df_list , to which dictionaries will be appended. This list of dictionaries will eventually be converted to a pandas DataFrame (this is the most efficient way of building a DataFrame row by row ).
- Creates an empty folder, bestofrt_posters , to store the downloaded movie poster image files.
- Creates an empty dictionary, image_errors , to fill to keep track of movie poster image URLs that don't work.
-
Loops through the Wikipedia page titles in
title_list
and:
- Stores the ranking of that movie in the Top 100 list based on its position in title_list . Ranking is needed so we can join this DataFrame with the master DataFrame later. We can't join on title because the titles of the Rotten Tomatoes pages and the Wikipedia pages differ.
-
Uses
tryandexceptblocks to attempt to query MediaWiki for a movie poster image URL and to attempt to download that image. If the attempt fails and an error is encountered, the offending movie is documented in image_errors . - Appends a dictionary with ranking , title , and poster_url as the keys and the extracted values for each as the values to df_list .
-
Inspects the images that caused errors and downloads the correct image individually (either via another URL in the
imageattribute's list or a URL from Google Images) -
Creates a DataFrame called
df
by converting
df_list
using the
pd.DataFrameconstructor .
Tasks
Task Description:
Inside the "for title in title_list:" loop in the Jupyter Notebook below:
Task Feedback:
Great! Check your solution by running the last cell in the notebook below, if you haven't already.
Workspace
This section contains either a workspace (it can be a Jupyter Notebook workspace or an online code editor work space, etc.) and it cannot be automatically downloaded to be generated here. Please access the classroom with your account and manually download the workspace to your local machine. Note that for some courses, Udacity upload the workspace files onto https://github.com/udacity , so you may be able to download them there.
Workspace Information:
- Default file path:
- Workspace type: jupyter
- Opened files (when workspace is loaded): n/a